

< 머신러닝을 위한 실전 데이타셋 > | 칼리드 엘 에맘,루시 모스케라,리처드 홉트로프 지음 |
심상진 옮김 | 한빛미디어
인공지능과 머신러닝 모델을 구축하기 위해서는 대량의 데이타가 필요하다. 대량의 데이타 또한 양질의 데이타로써 활용할 가치가 있어야 한다. 이를 위해서 합성 데이타가 많은 주목과 관심을 받아 오고 있다. 대량의 데이타를 필요로 하는 NVIDIA, IBM, 알파벳 등과 같은 IT 기업뿐만 아니라 인구조사국 같은 정부 기관도 모델 구축, 애플리케이션 개발, 데이타 배포를 지원하기 위해 다양한 유형의 데이타 합성 방법론을 채택하고 있다.
합성데이타는 실제 데이타가 아니라 실제 데이타에서 생성되어 실제 데이타와 통계 속성이 동일한 데이타를 말한다. 따라서 분석가는 합성 데이타셋으로 작업을 해도 실제 데이타에서 얻은 분석 결과와 동일한 분석 결과를 얻을 수 있다. 합성 데이타는 두가지 방법으로 합성할 수 있다. 첫번째는 실제 데이타셋 몇개로 실제 데이타의 분포와 구조를 포착하는 모델을 구축하는 것이다. 모델이 구축되면 합성 데이타는 해당 모델에서 샘플링되거나 생성되며, 모델이 실제 데이타를 제대로 표현한다면 합성 데이타는 실제 데이타와 통계적 특성이 유사하게 된다.
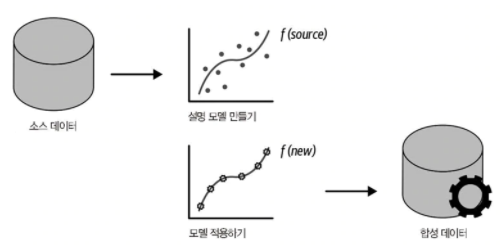
두번째는 실제 데이타없이 기존 모델이나 배경지식을 이용하여 생성하는 것이다. 특히 새로 도입된 공정이거나 분석가가 그 공정을 이해하지 못하거나 과거 데이타를 사용할 수 없는 경우, 분석가는 공정에 관련된 변수 간의 분포와 상관관계를 몇 가지로 간단하게 가정하고, 이를 기반으로 합성 데이타를 생성하게 된다.
이러한 합성 데이타는 여러 산업에 걸쳐 다방면으로 활용되고 있다. 제조 및 유통, 헬스케어 및 금융서비스, 교통 수단등 우리가 익히 알고 있는 여러 산업에서 사용되고 있다. 실제 데이타 접근이 어려울 경우 합성 데이타는 그 어느 방법보다도 좋은 해결책을 볼 수 있다. 데이타 합성을 비롯해 데이타 접근 시 사용할 수 있는 기술로 개인 정보 보호 강화 기술(PET)이 있다. 데이타 합성은 비지니스 기준을 최적화하는 많은 상황에서 강력한 접근법이다. 데이타 식별 시 개인 정보와 비개인 정보를 식별 가능한 스펙트럼으로 식별해야 한다.
데이타 합성이 조직의 우선 순위에 부합하는지 평가하기 위해서는 의사결정 프레임워크를 만들고 가장 적절한 프레임워크를 선택해야 한다. 그리고 이 프레임워크에 따라 프로세스 및 파이프라인을 구현해야하며, 규모에 맞게 구현된 합성으로 프로그램을 관리할 때 실질적으로 다양한 요소를 고려해야 한다.
데이타 합성을 위해서는 개별 데이타 분포를 제대로 이해해야 한다. 정규분포, 베이즈 분포, 푸아송 분포, 로그 분포, 이항 분포, 연령 분포, 요인 분포 등 다양한 유형의 분포로 해석할 수 있어야 한다. 이후 실제 데이타를 분석된 분포에 적합시키고, 분포로 부터 합성 데이타를 생성할 수 있어야 한다. 이때 합성 데이타의 분포 적합성을 측정할 수 있어야 하며, 과접합된 분포가 생기는 과적합 딜레마를 파악해야 한다. 그리고 적합하지 않은 임의의 데이타를 배제하는 단계를 수행해야 한다.
합성 데이타를 광범위하게 사용하고 채택하게 하려면 합성 데이타가 원본 데이타의 분석 결과와 유사한 분석 결과를 낼 수 있을 만큼 효용성이 높아야 한다. 이를 위해서는 합성 데이타의 효용성 평가가 이루어져야 한다. 이 과정은 작업부하 인식 평가와 일반적인 데이타 효용성 메트릭, 그리고 데이타 효용성의 주관적 평가로 이루어진다.
인공지능 및 머신러닝에는 제대로 된 데이타가 필요함을 알 수 있다. 특히 개인 정보의 경우 여러가지 법적인 문제로 인해 실제 데이타를 그대로 사용할 수 있는 경우는 거의 없다고 볼 수 있다. 이런 경우 실 데이타로 부터 가공된 임의의 데이타 또는 실 상황을 반영하는 가상의 데이타를 생성하는 기술이 꼭 필요하다. 이 책을 통해 데이타가 필요한 경우 어떻게 합성 데이타를 만들어 낼 수 있는지 제대로 이해할 수 있다. 또한 만들어진 합성 데이타가 얼마나 효용성이 있는지 평가하고 개인 정보에 관련한 규제를 얼마나 충분히 반영하는지 평가하는 방법도 동시에 얻을 수 있다.
기반 지식없이 읽기에는 조금 어려운 느낌은 있지만 관심을 가지고 읽어 나간다면 책에서 말하고하는 핵심 개념 및 방법에 대해서 이해하는데는 문제가 없을 것 같다. 다양한 방법으로 데이타를 합성해서 이용하고자 하는 사람이라면 꼭 한번 읽어볼 필요가 있다고 생각한다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
'꿈꾸는 책들의 도시' 카테고리의 다른 글
| [에세이] 아무튼, 식물 (0) | 2021.02.11 |
|---|---|
| [사회] 새로운 가난이 온다 (0) | 2021.02.11 |
| [에세이] 지구 좀 다녀오겠습니다 (0) | 2021.02.04 |
| [에세이] 오늘도 변화무쌍 (0) | 2021.02.03 |
| [자기계발] 김미경의 리부트 (0) | 2021.01.29 |

